
 超长字符串字段-前缀索引两宗罪
超长字符串字段-前缀索引两宗罪
# 超长字符串字段,前缀索引两宗罪
前缀索引并不是一个难理解的东西,但是这里面涉及到的一些细节,我相信很多同学都没有去深入了解过。
老规矩,前缀索引相关面试题的背诵版在文末。点击阅读原文可以直达我收录整理的各大厂面试真题
InnoDB 表中每一列索引的最大长度不能超过 767 字节,所以,对于某些比较长的字段,如果确实有建立索引的必要,使用前缀索引不仅能够避免索引长度超过限制,而且相对于普通索引来说,占用的空间和查询成本更小。
至于为什么说前缀索引占用的空间和查询成本更小,我们来直接上个例子:
假设表中存在一个邮箱 email 字段,我们在这个字段上面分别创建普通索引和前缀索引:
1)普通索引,包含了每行 email 记录的的整个字符串:alter table user add index index1(email);
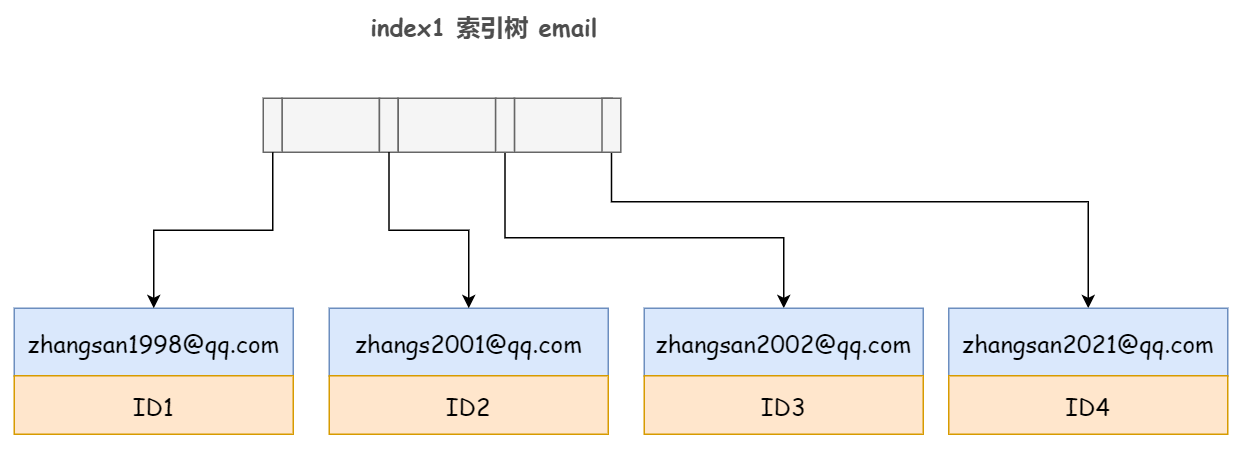
2)前缀索引,取每行 email 记录的前 6 个字节:alter table user add index index2(email(6));
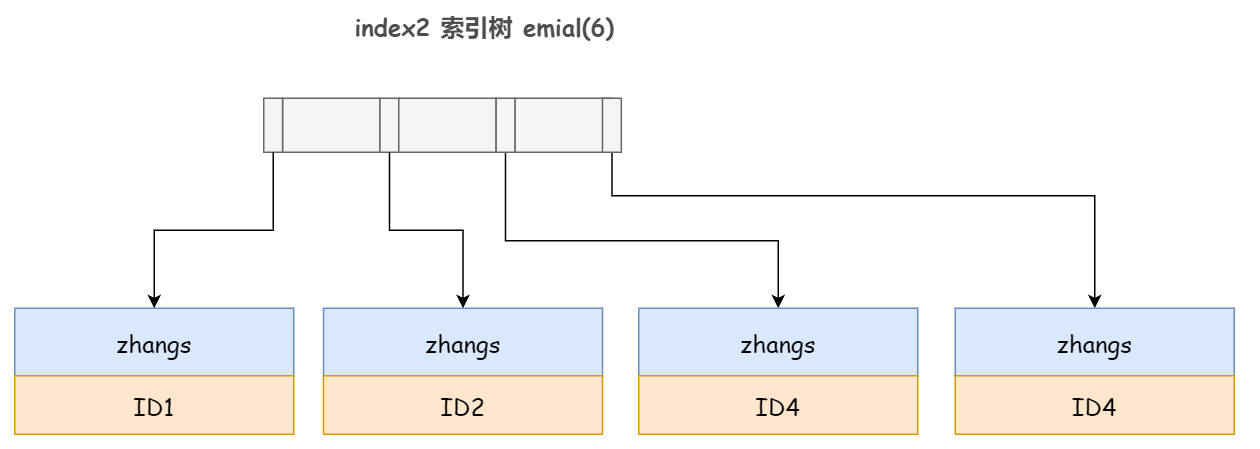
你可以看到,由于 email(6) 这个索引结构中每个 email 字段都只取前 6 个字节 zhangs,所以占用的空间比普通索引更小,这就是使用前缀索引的优势。
很好理解,对吧。
# 前缀索引一宗罪
但是,前缀索引这个占用空间更小的优势可能会带来额外的记录扫描次数。
举个例子,执行如下 sql 语句:
select * from user where email = 'zhangs2001';
1)对于普通索引 email 来说,执行顺序如下:
- 从 index1 索引树找到第一个满足索引值是 'zhangs2001' 的这条记录,并获取到主键 ID2 的值;
- 根据主键值回表查询,获取其他相应的记录,然后将获取到的结果加入结果集;
- 取 index1 索引树上刚刚查到的位置的下一条记录,发现已经不满足 email='zhangs2001' 的条件了,结束执行
这个过程中,只需要回表一次
2)对于前缀索引 email(6) 来说,执行顺序如下:
- 从 index1 索引树找到第一个满足索引值是 'zhangs' 的这条记录,并获取到主键 ID1 的值;
- 根据主键值回表查询,判断 email 的值到底是不是 'zhangs2001',发现并不是,这行记录丢弃
- 取 index1 索引树上刚刚查到的位置的下一条记录,发现 email 前缀仍然满足 'zhangs',则获取到主键 ID2 的值;然后根据主键值回表查询,返现 email 的值确实是 'zhangs2001',则将这行记录加入结果集
- 如此重复,直到 email 前缀不再是 'zhangs',则执行结束
可以看到,这个过程中,需要回表四次
这就是前缀索引的第一宗罪:使用前缀索引可能会增加记录扫描次数与回表次数,影响性能

不过呢,我们做一些细微的改变,就能让这个前缀索引回表次数大大减少。
把 index2-email(6) 这个前缀索引改成 index3-email(7):

再来看上面这个例子,执行顺序如下:
- 从 index1 索引树找到第一个满足索引值是 'zhangs2' 的这条记录,并获取到主键 ID2 的值;
- 根据主键值回表查询,判断 email 的值到底是不是 'zhangs2001',发现确实是,则将这行记录加入结果集
- 取 index1 索引树上刚刚查到的位置的下一条记录,发现 email 前缀不满足 'zhangs2',则执行结束
可以看到,相对于普通索引,email(7) 这个前缀索引同样只需要回表一次,并且占用更少的索引空间。
# 前缀索引二宗罪
看下面这条 SQL 语句:
select id,email from user where email = 'zhangs2001';
如果使用 index1 索引(即 email 整个字符串的索引结构)的话,可以利用上覆盖索引,从 index1 索引树上查到结果后就可以返回了,不需要进行回表。
而如果使用 index2(即 email(6) 前缀索引结构)的话,就不得不再次根据主键值去回表判断 email 字段的值是否真的是 'zhangs2001'。也就是说,使用前缀索引就用不上覆盖索引对查询性能的优化了。
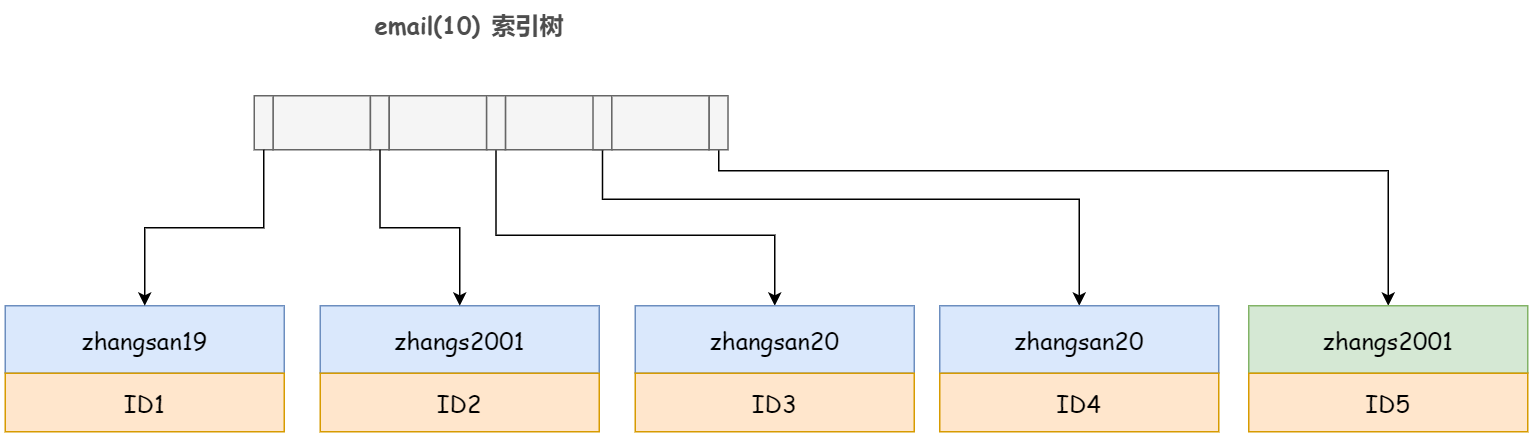
那有同学就要问了,如果是 email(10) 呢,这个前缀索引不就完全包含了 zhangs2001 的所有信息了嘛,还需要回表吗?
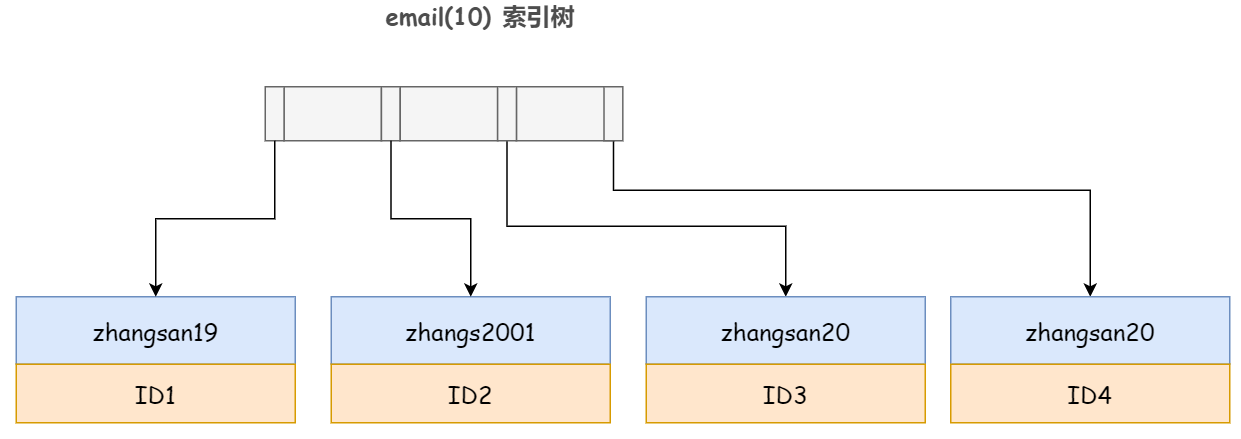
答案是并不能阻止 InnoDB 的回表,因为 InnoDB 并不能确定前缀索引的定义是否截断了完整信息。谁知道你会不会又增加一个 'zhangs20012' 的记录呢,对吧。
# 如何定义前缀索引的长度
索引选取的越长,占用的磁盘空间就越大,相同的数据页能放下的索引值就越少,搜索的效率也就会越低。
在上面的例子中我们提到,只需要把前缀索引从 email(6) 改成 email(7),就可以大大减少记录扫描和回表的次数,所以,在定义前缀索引的时候,我们需要在占用空间和搜索效率之间做一个权衡 trade-off。
事实上,我们在建立前缀索引时关注的是区分度,区分度越高,意味着重复的键值越少,所以区分度越高越好。
对于索引来说,什么是区分度呢,很简单,就是这个索引上有多少个不同的值。建立出来的索引上拥有越多不同的值,那么这个索引的区分度就越高。
因此,我们可以通过统计索引上有多少个不同的值来判断要使用多长的前缀。可以使用下面这个语句,计算出 email 列上有多少个不同的值,记作 email_length:
select count(distinct email) as email_length from user;
然后,依次选取不同长度的前缀来看区分度,比如我们要看前缀索引的长度是 6~10 时候的区分度,可以用这个语句:
select count(distinct left(email,6))as email_length_6,
count(distinct left(email,7))as email_length_7,
count(distinct left(email,8))as email_length_8,
count(distinct left(email,9))as email_length_9,
count(distinct left(email,10))as email_length_10,
from user;
当然了,既然我们使用了前缀索引,那么就不可避免的会损失区分度,就像我们前面所说的,谁也不知道会不会又新增出一条记录完全踩中前缀但是又不满足判断条件。所以我们需要预先设定一个可以接受的区分度损失比例,比如 5%。然后找出不小于 email_length * (1 - 5%) 的值,假设这里 email_length_8、email_length_9 都满足,我们就可以选择前缀长度为 8。
# 前缀索引的区分度不够高怎么办
我当时实习的时候就遇到过这个问题,字段(假设这个字段名是 a)超级超级长,远大于 InnoDB 的限制 767 字节,普通索引肯定是不可能了,前缀索引就算是长度定义成 767 都还是存在区分度不高的情况,但是又存在根据这个字段进行查询的挺频繁的一个需求。
一个很常见的解决手段就是 Hash。
对这个超长字段 a 进行 hash(假设命名为 a_hash) 存入数据库,然后对这个 hash 值建立索引,由于 hash 值同样可能存在冲突,也就是说两个不同的 a 通过 Hash 函数得到的结果可能是相同的,所以我们在查询语句的 where 部分还需要进行一次精确判断
# 假设输入的字段是 input_a
select * from user where hash(input_a) = a_hash and input_a = a;
不过使用 Hash 这种方式有个众所周知的缺点,那就是不支持范围查询了,只能等值查询。
最后放上这道题的背诵版:
🥸 面试官:前缀索引了解吗,为什么要建前缀索引
😎 小牛肉:前缀索引就是选取字段的前几个字节建立索引。首先,InnoDB 限制了每列索引的最大长度不能超过 767 字节,所以,对于某些比较长的字段,如果确实有建立索引的必要,使用前缀索引不仅能够避免索引长度超过限制,而且相对于普通索引来说,占用的空间和查询成本更小。
不过前缀索引可能会导致两个问题:
第一个,使用前缀索引可能会增加记录扫描次数与回表次数,影响性能。针对这一点呢,其实前缀索引长度的选取还是很重要的,可能前缀定义的长一点,就能够大幅减少记录扫描次数和回表次数,所以,在建立前缀索引的时候,我们需要在占用空间和搜索效率之间做一个权衡
第二个,使用前缀索引其实就没法用覆盖索引对查询性能的优化了,因为 InnoDB 并不能确定前缀索引的定义是否截断了完整信息,就算是完全踩中了前缀索引,InnoDB 还得回表确认一次到底是不是满足条件了。